
O que é SLA: entenda o significado de Service Level Agreement

Quando um sistema cai e o cliente liga reclamando, a primeira pergunta do gestor de TI é: “qual é o nosso SLA para esse serviço?” Se a resposta for vaga ou inexistente, o problema não é técnico — é de governança. O SLA é o documento que transforma expectativas informais em compromissos mensuráveis.
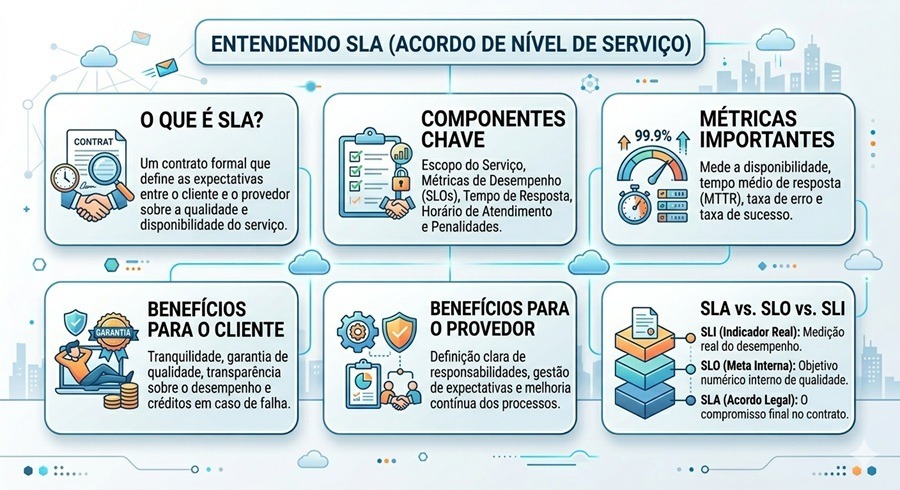
SLA (Service Level Agreement), ou Acordo de Nível de Serviço, é o contrato formal que define as métricas de qualidade, disponibilidade e suporte que um prestador de serviços se compromete a entregar ao cliente. Na área de TI, ele é a espinha dorsal da relação entre provedores de infraestrutura, equipes de operações e usuários do negócio. Neste guia completo atualizado para 2026, você vai entender o que é SLA, como calcular, quais métricas usar, os tipos existentes e como o conceito evoluiu com o SRE.
O que é SLA em TI?
O SLA (Service Level Agreement) é um acordo contratual entre um provedor de serviços e seu cliente que especifica, de forma mensurável, o nível mínimo de qualidade que será entregue. Ele responde a perguntas como: qual o tempo máximo para resolver um incidente crítico? Qual a disponibilidade mínima garantida do sistema? O que acontece se o provedor não cumprir o acordado?
O SLA define três elementos centrais. O escopo do serviço: o que está coberto e o que não está. As métricas e metas: os indicadores que serão medidos e os valores-alvo para cada um. E as consequências: penalidades ou créditos em caso de descumprimento.
Na prática, o SLA é a ferramenta que transforma a relação entre TI e negócio de uma conversa de expectativas em um compromisso com accountability — e é por isso que gestores de TI, provedores de cloud e equipes de SRE o tratam como documento estratégico.
Tipos de SLA
Existem três modelos principais, cada um adequado a contextos diferentes.
SLA focado no cliente
Acordo personalizado para um cliente específico, considerando suas necessidades e prioridades únicas. É mais trabalhoso de administrar mas entrega atendimento diferenciado. Exemplo: uma clínica médica que depende de sistemas críticos 24h pode exigir um SLA personalizado com tempo de resposta de 30 minutos para incidentes P1, diferente do que seria acordado com um cliente de escritório.
SLA focado no serviço
O mesmo nível de serviço vale para todos os clientes que contratam determinado serviço. Mais simples de administrar e escalar. Exemplo: um provedor de cloud que garante 99,9% de disponibilidade para todos os assinantes do plano empresarial, independentemente do cliente.
SLA multinível
Combina elementos dos dois modelos anteriores, criando camadas de acordo conforme criticidade. Comum em grandes organizações onde setores diferentes têm prioridades diferentes. Exemplo: um grupo hospitalar com SLA nível 1 para UTI (suporte 24h, resposta imediata) e SLA nível 2 para áreas administrativas (suporte em horário comercial).
Além dos tipos acima, existe o conceito de SLA interno (OLA — Operational Level Agreement), que formaliza compromissos entre equipes internas da mesma organização — por exemplo, entre a equipe de infraestrutura e o service desk.
Principais métricas de SLA em TI
A escolha das métricas certas é decisiva para a eficácia do SLA. As mais utilizadas em operações de TI são:
Disponibilidade (Uptime)
A métrica mais fundamental. Geralmente expressa em percentual mensal ou anual. A tabela abaixo mostra o impacto real de cada nível de disponibilidade:
| Disponibilidade | Downtime por mês |
|---|---|
| 99,0% Dois noves | 7h 18min |
| 99,5% Dois noves e meio | 3h 39min |
| 99,9% Três noves | 43min |
| 99,99% Quatro noves | 4min 22seg |
| 99,999% Cinco noves | 26seg |
Para sistemas de missão crítica como bancos e e-commerce, quatro ou cinco noves são o padrão. Para sistemas internos de suporte, 99,5% costuma ser suficiente.
Tempo de resposta e resolução
O tempo de resposta é o prazo máximo para a equipe de suporte começar a atender um chamado após sua abertura. O tempo de resolução é o prazo máximo para o serviço ser restaurado. Ambos variam conforme a prioridade do incidente.
Um exemplo típico de matriz de prioridades em SLA de Service Desk:
| Prioridade | Resposta | Resolução |
|---|---|---|
| P1Crítico — sistema fora | 15 min | 4 h |
| P2Alto impacto | 1 h | 8 h |
| P3Médio impacto | 4 h | 24 h |
| P4Baixo impacto | 8 h | 72 h |
MTTR e MTBF
O MTTR (Mean Time to Restore) mede o tempo médio para restaurar o serviço após uma falha. O MTBF (Mean Time Between Failures) mede o intervalo médio entre falhas. Ambos são indicadores frequentemente incorporados como metas em SLAs de infraestrutura.
Taxa de cumprimento do SLA
Percentual de chamados ou incidentes que foram atendidos dentro dos prazos acordados. É a métrica de monitoramento contínuo mais usada em reports mensais de SLA.
Calculadora de SLA
Criamos uma calculadora de SLA que demonstra o downtime dos elementos de infraestrutura, conforme SLA. É importante ressaltar que SLAs acima de 99% escalam os custos de forma exponencial com uso de múltipla redundância, autoscaling, entre outros. Portanto, é importante avaliar o real benefício para o seu negócio.
SLA vs SLO vs SLI: a tríade do SRE
Com a adoção de práticas de SRE (Site Reliability Engineering), o vocabulário de nível de serviço evoluiu. Entender a distinção entre esses três termos é essencial para equipes técnicas modernas.
O SLI (Service Level Indicator) é a métrica bruta medida em tempo real: taxa de erros, latência P99, disponibilidade. É o dado puro, sem julgamento de valor.
O SLO (Service Level Objective) é o objetivo interno da equipe de engenharia para um SLI específico. Por exemplo: “99,9% das requisições devem ter latência abaixo de 500ms em uma janela de 30 dias”. O SLO é mais rigoroso que o SLA — é o que a equipe tenta atingir internamente.
O SLA (Service Level Agreement) é o compromisso externo e formal com o cliente. Geralmente um pouco menos rigoroso que o SLO, criando uma margem de segurança operacional. Se o SLO for violado, a equipe já sabe que o SLA está em risco antes que o cliente perceba.
O error budget é o corolário desse sistema: a quantidade de “tempo de falha” permitida antes que o SLO seja violado. Se o error budget está se esgotando rapidamente, a engenharia precisa pausar novos deploys e focar em confiabilidade.
Essa tríade SLI → SLO → SLA é o padrão de governança de confiabilidade adotado por Google, Amazon, Netflix e pela maioria das organizações com práticas modernas de observabilidade.
Como calcular e estruturar um SLA
A construção de um SLA eficaz segue cinco etapas.
O primeiro passo é mapear os serviços e suas criticidades: liste todos os serviços que serão cobertos, classifique-os por impacto no negócio e defina quais merecem SLAs mais rigorosos.
O segundo é analisar o histórico operacional: use dados reais de monitoramento para entender qual o MTTR atual, qual a disponibilidade histórica e quais tipos de incidentes são mais frequentes. SLAs baseados em dados reais são muito mais sustentáveis do que metas aspiracionais.
O terceiro é definir métricas e metas: escolha os indicadores mais relevantes para cada serviço. Evite excesso de métricas — foque nas que realmente impactam o negócio.
O quarto é documentar escopo, exclusões e penalidades: especifique o que está coberto (e o que não está), os horários de suporte, os canais de atendimento e as consequências de descumprimento (créditos de serviço, penalidades contratuais).
O quinto é implementar monitoramento e revisão periódica: um SLA sem monitoramento é papel. Configure alertas que disparem antes de violar as metas, implemente dashboards de acompanhamento e revise o SLA anualmente ou após mudanças significativas na infraestrutura.
SLA e monitoramento: como garantir o cumprimento
O cumprimento do SLA começa muito antes de um incidente acontecer. Plataformas de monitoramento de infraestrutura com alertas configurados por threshold permitem que a equipe aja proativamente — antes que a degradação se torne uma violação.
A integração entre monitoramento e Service Desk é particularmente poderosa: quando um evento de monitoramento indica risco de violação de SLA, um chamado é aberto automaticamente com toda a informação técnica necessária, reduzindo o MTTD e acelerando a resposta. Essa automação é o que diferencia operações reativas de operações com alta disponibilidade genuína.
99,9% de uptime não acontece por acidente. É resultado de engenharia.
Estruturamos arquiteturas de monitoramento proativo que elevam sua disponibilidade de forma gradativa e mensurável, com SLA garantido em contrato.
Conclusão
O SLA é muito mais que um documento contratual: é a base de uma operação de TI orientada a resultados e accountability. Quando bem estruturado — com métricas baseadas em dados reais, metas realistas e monitoramento automatizado — ele protege tanto o provedor quanto o cliente e cria as condições para melhoria contínua.
Em 2026, o SLA moderno se integra à tríade SLI/SLO/SLA do SRE, ao error budget e às práticas de observabilidade para criar um sistema de governança de confiabilidade que vai muito além do contrato. Se você quer estruturar ou revisar os SLAs da sua operação com apoio técnico especializado, fale com nossos especialistas.