
Post Mortem: Guia, Template e Métricas SRE

Toda equipe de operações em algum momento percebe a mesma armadilha: incidentes se repetem, lições viram apresentações esquecidas e o time fica preso em um ciclo reativo. O post mortem nasceu para quebrar esse ciclo. Vale destacar que ele não é só um relatório formal — é o mecanismo cultural que transforma cada incidente em aprendizado sistêmico mensurável.
Este guia foi reescrito em 2026 com a visão moderna de SRE praticada em equipes brasileiras. Você vai encontrar gatilhos ligados a SLO, um roteiro passo a passo da reunião, um template editável e a conexão direta com as métricas DORA. No final, um checklist e uma seção de perguntas frequentes encerram o material.
Em resumo, se a sua operação ainda trata incidente como caso isolado, o post mortem corretamente conduzido reduz MTTR, baixa a taxa de recorrência e devolve previsibilidade para times de plantão. Vamos passar pelos sete eixos que diferenciam um post mortem efetivo de um relatório burocrático.
O que é Post Mortem?
Post mortem é a análise estruturada conduzida depois de um incidente significativo, com o objetivo de entender o que aconteceu, por que aconteceu e o que mudar para evitar recorrência. Ou seja, é um exercício de causa raiz somado a um plano de ação rastreável. O nome vem do latim e significa “depois da morte” — uma metáfora médica que se popularizou em engenharia.
A prática ganhou tração quando o Google publicou o capítulo de cultura de post mortem na publicação clássica do Google SRE, codificando o princípio do análise sem culpa. A partir daí, o post mortem deixou de ser ferramenta exclusiva de aviação e indústria para se tornar uma engrenagem central do guia completo de Site Reliability Engineering.
Por isso, hoje, o post mortem ocupa três funções simultâneas em uma operação madura: documentar a memória institucional, transformar dor em melhoria e proteger a confiabilidade contratada com o cliente. Em síntese, sem ele, o conhecimento fica preso em quem viveu o incidente.
Quando conduzir um post mortem: gatilhos baseados em SLO e impacto
Nem todo incidente exige post mortem completo. Exigir um relatório a cada falha cria fadiga e devaluação do processo. Por outro lado, deixar passar incidentes relevantes apaga o sinal de aprendizado. A solução é definir gatilhos objetivos, idealmente acoplados aos seus indicadores de confiabilidade.
Os gatilhos mais usados combinam consumo de error budget, duração da falha, escopo de usuários afetados e severidade percebida. Vale dizer que cada empresa calibra esses limites de acordo com criticidade. A tabela abaixo mostra um modelo de severidade que conecta cada nível ao tipo de análise exigida.
| Severidade | Error budget consumido | Análise exigida |
|---|---|---|
| SEV1Indisponibilidade total | ≥ 50% | Post mortem completo |
| SEV2Degradação severa | 20% a 50% | Post mortem completo |
| SEV3Impacto parcial | 5% a 20% | Post mortem leve |
| SEV4Near-miss / desvio | < 5% | Registro com lições |
Além desses critérios quantitativos, considere gatilhos qualitativos. Por exemplo: incidentes que exigiram escalonamento fora do plantão, falhas com risco de perda de dados, eventos que violaram compromissos de SLA com cliente externo e quase-incidentes considerados graves pela equipe. Em última análise, o gatilho confirma que o aprendizado vale o esforço da reunião.
Cultura blameless: o pré-requisito que faz o post mortem funcionar
A característica mais importante de um post mortem eficaz é a cultura sem culpa. O foco está em fatores sistêmicos, não em responsabilizar pessoas. Por exemplo, se um engenheiro rodou um comando errado em produção, a pergunta não é “por que ele errou”, mas sim “por que era possível rodar esse comando sem revisão automatizada”. Dessa forma, o sistema é o réu, não o operador.
Times que conduzem post mortems punitivos observam um padrão previsível: as pessoas param de reportar problemas e param de documentar erros honestos. Como resultado, o aprendizado que o processo deveria gerar simplesmente desaparece. O blameless protege a operação contra esse efeito.
Vale ressaltar a diferença entre post mortem e RCA. O RCA tradicional foca em encontrar a causa raiz mecanicamente, frequentemente em um único componente. O post mortem moderno, principalmente em ambientes distribuídos, reconhece que como sistemas complexos falham envolve múltiplas causas contribuintes interagindo. Por conseguinte, o relatório precisa narrar a cadeia de eventos e os fatores de contexto, não só apontar um culpado técnico.
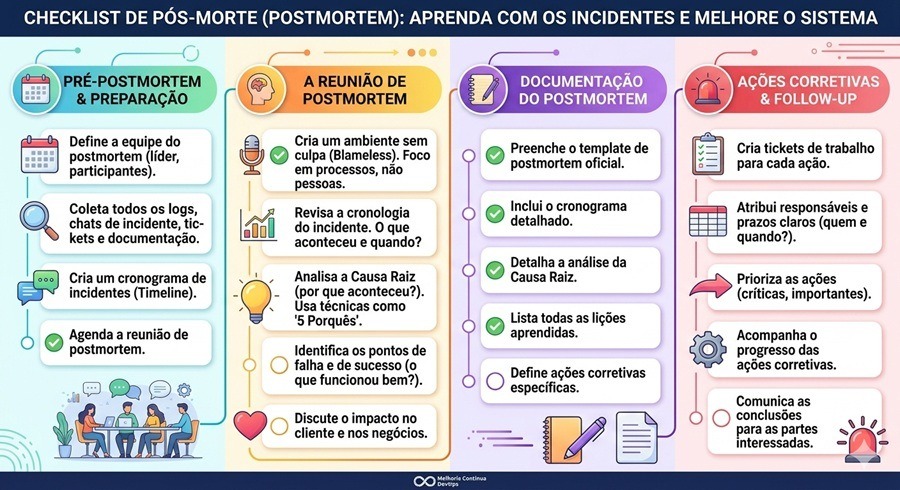
Como conduzir um post mortem passo a passo
Um post mortem bem conduzido segue um roteiro repetível. A reunião costuma ter timebox entre 90 minutos e 3 horas, com facilitador, scribe e participantes que viveram o incidente. Em seguida, o documento é fechado, revisado e publicado no repositório interno de aprendizados. As quatro etapas críticas estão detalhadas a seguir.
Construir a linha do tempo do incidente
A primeira etapa é reconstruir cronologicamente o que aconteceu, com timestamps precisos. A linha do tempo deve cobrir quando o problema começou, quando foi detectado, quando foi escalado e quais ações de mitigação produziram efeito. Dados brutos vêm de logs, métricas e traces — em outras palavras, dos pilares de observabilidade que sustentam o diagnóstico.
Antes de tudo, exporte os artefatos de telemetria do período do incidente para uma planilha auxiliar. Em seguida, o facilitador escreve a timeline em ordem, marcando cada evento como detecção, decisão ou ação. Esse rigor temporal expõe gargalos de detecção que viram input direto para melhorias de monitoramento.
Investigar a causa raiz com os 5 Porquês
Depois da timeline pronta, a equipe escava a cadeia causal. A técnica dos 5 Porquês é um ponto de partida útil: a cada resposta sobre o que causou o problema, pergunte “por quê” novamente. A cada iteração, a investigação se aprofunda das camadas técnicas para as camadas processuais e organizacionais. Posteriormente, a equipe consolida causas contribuintes em um diagrama de Ishikawa.
Cabe ressaltar que a técnica é subjetiva. Não tem nada de errado em usá-la para levantar as primeiras hipóteses, mas valide cada conclusão com evidências de telemetria. Times maduros combinam 5 Porquês com análise de pull requests, mudanças de configuração e correlações entre alertas. Assim, a hipótese vira diagnóstico.
Avaliar e quantificar o impacto
Impacto sem número é fraco. Por isso, o post mortem precisa quantificar quantos usuários foram afetados, qual percentual de requisições falhou, quanto da janela de erro foi consumida e quanto de receita ou contrato ficou em risco. Outro ponto importante: registre como o time soube, ou seja, qual foi o sinal que disparou a detecção e como ele se compara aos quatro sinais de ouro de SRE.
A consequência prática é direta: quando o impacto está quantificado, a priorização das ações vira óbvia. Por exemplo, uma ação que evita 90% do risco residual sobe imediatamente no backlog. Sem o número, todas as ações parecem urgentes — e nenhuma fica pronta.
Definir action items com dono e prazo
A última etapa fecha o ciclo. Cada lição vira um action item com três campos obrigatórios: dono, prazo e critério de conclusão verificável. Action items vagos como “melhorar monitoramento” não saem do papel. Comparativamente, “adicionar alerta para latência P99 superior a 500 ms na rota /checkout, dono Maria, prazo 2 sprints” gera resultado mensurável.
Por fim, registre o link do issue ou ticket onde a ação será rastreada. Em seguida, revise o backlog de ações de post mortems anteriores no mesmo encontro — itens não concluídos contam como dívida operacional e precisam ser repriorizados ou abandonados explicitamente.
Template de post mortem: estrutura, campos e checklist
Um template editável reduz fricção e padroniza a leitura. Você pode partir de um modelo próprio ou adaptar uma das opções da coleção pública de modelos do dastergon no GitHub, que reúne formatos consagrados do SRE Book, Azure e Elastic. As seções essenciais estão descritas abaixo.
| Seção | Conteúdo / Como preencher | Por que importa |
|---|---|---|
| Cabeçalho | ID, data, severidade, autores, status do documento | Garante rastreabilidade e busca futura |
| Resumo executivo | 3 a 5 linhas com impacto, causa e ações principais | Permite leitura rápida por liderança |
| Linha do tempo | Eventos com timestamps em UTC e fuso local |
Expõe lacunas de detecção e resposta |
| Causa raiz e contribuintes | Análise técnica, processual e organizacional | Evita diagnóstico raso ou unicausal |
| Impacto quantificado | Usuários, requisições, receita, SLO consumido |
Justifica priorização das ações |
| O que funcionou bem | Boas decisões e respostas eficazes | Reforça práticas a manter |
| Action items | Tabela com ação, dono, prazo, ticket vinculado | Transforma aprendizado em melhoria real |
Inclua um checklist final no template para validar a qualidade do documento antes da publicação. Itens recomendados: cada action item tem dono e prazo, a timeline cobre detecção e mitigação, o impacto está quantificado, a linguagem é blameless e há link para os artefatos de telemetria do incidente.
Métricas que mostram se o seu post mortem funciona
Post mortem sem métrica vira ritual. Para saber se o seu programa está dando resultado, conecte os documentos a indicadores objetivos. Dois conjuntos se destacam: as métricas operacionais clássicas e o framework DORA.
No lado operacional, acompanhe MTTD (tempo até detecção), MTTR (tempo até recuperação) e taxa de recorrência por categoria de causa. Adicionalmente, monitore o consumo do error budget mês a mês e a aderência ao SLO definido para cada serviço crítico. Quando o SLO degrada de forma consistente, o post mortem é o instrumento que diagnostica a tendência.
Já a pesquisa do programa DORA oferece quatro métricas que revelam a saúde do seu ciclo de entrega: lead time, deployment frequency, change failure rate e MTTR. Em particular, change failure rate caindo é evidência direta de que action items de post mortem geraram impacto. Por isso, vincule cada PR de remediação ao número do post mortem que o originou — assim, fica fácil somar a economia de incidentes evitados.
Erros comuns que esvaziam um post mortem
Alguns padrões repetitivos transformam um bom processo em teatro corporativo. Identifique e corrija cada um deles antes que viram cultura.
O primeiro erro é o post mortem virar relatório burocrático que ninguém lê. A causa quase sempre é falta de patrocínio: se a liderança não cobra leitura e priorização, o documento morre na primeira página. Em contrapartida, equipes que abrem a sprint review com a leitura do post mortem mais recente mantêm o processo vivo.
Outro erro frequente são as ações genéricas tipo “documentar melhor” ou “treinar a equipe”. Ações sem critério de conclusão verificável não saem do backlog. Substitua por entregáveis específicos com prazo curto. Da mesma forma, evite o post mortem que culpa fornecedor terceirizado sem investigar quais salvaguardas internas faltaram — esse é o sintoma clássico do antipadrão “vendor finger-pointing”.
Por fim, cuidado com a falta de follow-up. Marque o status de cada action item em revisões mensais. Quando a operação atinge maturidade, o backlog de ações pendentes encolhe, a recorrência de incidentes cai e a equipe começa a confiar de verdade no processo.
Transformamos operações reativas em engenharia de confiabilidade (SRE).
Implementamos SLIs, SLOs e Error Budgets para reduzir o MTTR e eliminar a fadiga de alertas das suas equipes de operação.
Conclusão
O post mortem moderno é mais do que um relatório: é o ciclo que conecta detecção, resposta, aprendizado e melhoria contínua. Quando a sua operação adota gatilhos objetivos, cultura blameless, técnica de causa raiz e action items rastreáveis, cada incidente passa a render dois resultados — a mitigação imediata e a redução estrutural de risco no longo prazo.
Em síntese, comece pequeno. Escolha um incidente recente, aplique o template apresentado neste guia, defina três action items com dono e prazo e marque a primeira revisão para a próxima sprint. Em seguida, repita o ciclo até que o processo fique natural na rotina do time.
Se a sua equipe quer estruturar um programa completo de confiabilidade — com SLOs definidos, observabilidade integrada e consultoria de SRE dedicada — a OpServices apoia desde a definição dos indicadores até o ferramental de produção. Fale com um especialista e descubra como transformar incidentes em vantagem operacional duradoura.
Perguntas Frequentes
O que é um post mortem em TI?
Como fazer um post mortem de incidente?
timestamps de detecção, escalonamento e mitigação. Em seguida, investigue a causa raiz e as causas contribuintes usando técnicas como 5 Porquês e Ishikawa. Depois, quantifique o impacto em usuários, requisições, error budget consumido e receita. Por fim, defina action items com dono, prazo e critério de conclusão verificável, e registre o documento em um repositório interno acessível a todo o time.O que é blameless post mortem?
Qual a diferença entre post mortem e RCA?
Quando devo conduzir um post mortem?
SLO com consumo significativo de error budget, impacto em usuários acima do seu threshold definido, escalonamento fora do plantão, risco de perda de dados ou degradação de segurança. Near-misses considerados graves pela equipe também justificam um post mortem leve. Não exija o relatório completo para todo incidente: criar fadiga devalua o processo. Defina níveis de severidade SEV1 a SEV4 e conecte cada nível ao tipo de análise exigida para manter o equilíbrio entre cobertura e custo operacional.