
Continuous profiling vs APM: quando usar cada um
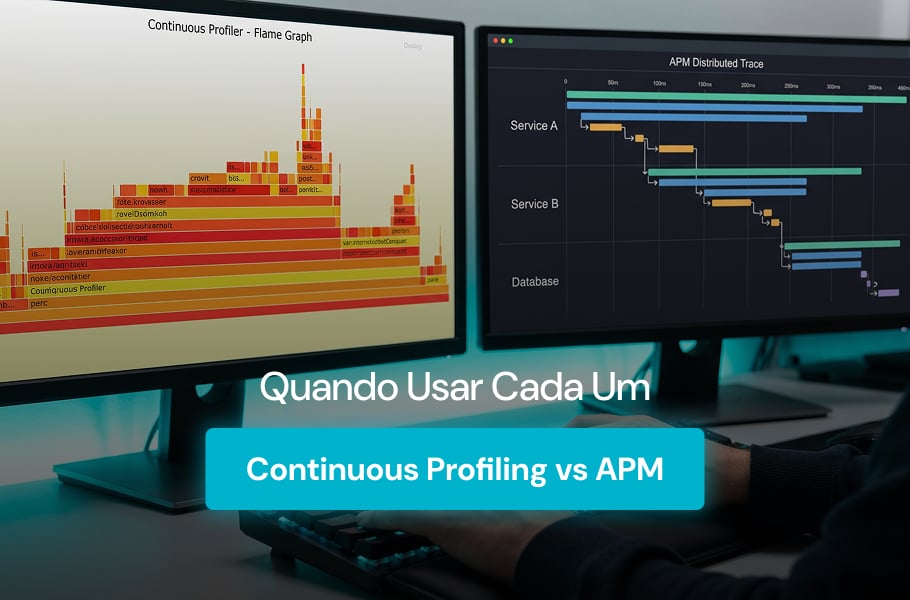
Um time chega no on-call às 3h da manhã com um alerta de p99 estourado. O APM mostra que o serviço de checkout está lento. A chamada interna para o cálculo de frete aparece como 4x mais devagar do que ontem. Até aí, ótimo. Mas o APM para por aí. Não diz qual função, qual loop ou qual alocação está consumindo CPU dentro daquele serviço.
Esse é o ponto exato onde continuous profiling entra. Enquanto o APM responde “onde está a lentidão na arquitetura”, o profiling contínuo responde “qual linha de código está pesando agora”. Também responde como esse perfil mudou após o último deploy. Não são tecnologias concorrentes. São camadas diferentes da mesma operação.
Este artigo compara as duas abordagens lado a lado. Em síntese, vamos detalhar o que cada uma mede e qual o overhead em produção. Também cobrimos quando uma sozinha já basta, quando você precisa das duas e como decidir o que adotar primeiro.
O que é APM e que tipo de pergunta ele responde
APM significa Application Performance Monitoring. Em essência, ele instrumenta a aplicação para capturar requests, mede o tempo de cada etapa e cria um mapa de dependências entre serviços. Cada request vira um trace e cada operação dentro daquele request vira um span.
O que o APM faz bem é responder perguntas sobre o caminho da requisição. Por exemplo: qual endpoint passou do p95 alvo, em qual serviço o tempo se perde e qual chamada externa está degradada. Esse é o modelo RED clássico: rate, errors, duration.
Para um aprofundamento sobre como o APM se encaixa no monitoramento moderno, vale ler o guia o que é APM e como implementar. Ademais, a definição do método central nas métricas que o APM coleta está explicada no artigo sobre o método RED.
O ponto fraco do APM é a granularidade. Ele enxerga até o nível do span e do serviço, mas não desce até a função. Se um span de process_payment leva 800ms, o APM informa essa lentidão. Mas não diz se o gargalo está no hash de senha, na serialização JSON ou em uma alocação que dispara o garbage collector com frequência.
O que é continuous profiling e que tipo de pergunta ele responde
Continuous profiling é a prática de manter um profiler rodando 24×7 em produção. O agente coleta amostras de stack trace a baixa frequência, em geral 19 a 100 Hz por thread. Em seguida, armazena os perfis em um backend para consulta posterior. O profiler é leve o suficiente para nunca sair do ar.
O profiling responde uma pergunta central: qual função está consumindo o tempo de CPU agora. Outras variantes incluem “qual rota aloca mais memória” ou “qual loop tem lock contention”. Também responde “como o perfil de CPU mudou entre o release de ontem e o de hoje”. Ferramentas modernas usam eBPF para coletar amostras sem instrumentar nenhuma linha de código.
A representação visual mais comum é o flame graph. Brendan Gregg popularizou esse formato em seu trabalho sobre visualização de performance. Cada barra horizontal representa uma função e a largura indica o tempo proporcional de CPU. Em segundos, o engenheiro identifica a função mais cara.
Para o panorama completo da técnica, com cobertura de ferramentas como Pyroscope, Parca e Universal Profiling, o guia técnico de profiling de aplicações em produção entra em todos os detalhes de configuração, overhead e visualização.
A diferença prática: granularidade, contexto e overhead
A separação fica nítida quando você olha o que cada ferramenta entrega no momento da investigação. O APM dá contexto de negócio: qual usuário, qual rota, qual request específica. Por outro lado, o profiling dá contexto de execução: qual função, qual linha, qual padrão de alocação.
Em situações cotidianas, isso muda o ponto de partida do troubleshooting. Por exemplo: se o alerta diz “p99 do checkout subiu 40%”, o APM responde “qual etapa do checkout está lenta”. Em seguida, o profiling responde “qual função dentro daquela etapa está consumindo CPU”. Ambos importam, mas em ordem diferente.
Outro ponto crítico é o overhead. APMs modernos tipicamente ficam entre 1 e 3% de overhead com sampling. Profilers contínuos baseados em eBPF, como Parca e Universal Profiling, reportam consistentemente menos de 1% de CPU. Pyroscope típico fica entre 2 e 5%. Para sistemas com SLA agressivo, esse delta importa.
Comparativo lado a lado
A tabela abaixo resume as diferenças nas dimensões que mais pesam na hora de escolher e operar cada ferramenta no dia a dia.
| Dimensão | APM | Continuous profiling |
|---|---|---|
| Granularidade | Span e serviço | Função e linha de código |
| Pergunta dominante | Onde a requisição perde tempo | Por que o código consome CPU |
| Contexto de negócio | Nativo (usuário, rota, tenant) | Indireto via correlação com trace |
| Overhead típico em produção | 1 a 3% com sampling | Menos de 1% com eBPF; 2 a 5% sem |
| Instrumentação | SDK ou agent por linguagem | eBPF zero-code ou SDK |
| Cardinalidade de dados | Alta (trace por request) | Média (perfis agregados por janela) |
| Custo de armazenamento | Alto sem sampling | Médio com janela e retenção curta |
| Comparação antes/depois | Por métricas agregadas | Diff de perfis entre releases |
Em síntese, o APM ganha em contexto de negócio e visão arquitetural. O profiling ganha em profundidade de código e detecção de regressão fina. Daí vem a regra prática: nenhum dos dois sozinho responde tudo, mas cada um sozinho responde muito.
Quando APM sozinho já basta
Nem toda operação precisa adicionar um quarto sinal de observabilidade. Times com aplicações estáveis, sem hotspot recorrente de CPU e com gargalo dominante em chamadas externas ou banco extraem 90% do valor só com APM. Adicionar profiling nesse cenário gera custo operacional sem retorno claro.
APM resolve sozinho a maior parte dos casos com sintomas clássicos. Isso inclui latência alta de request, aumento de erros 5xx ou degradação de uma dependência externa. O contexto de quem chamou e em qual rota costuma bastar para identificar a causa. Para entender melhor essa métrica central, consulte o artigo sobre latência em sistemas distribuídos.
Da mesma forma, times pequenos com operação enxuta rendem mais ao consolidar o orçamento em APM bem configurado. Espalhar atenção entre duas ferramentas distintas dilui o ganho. O sinal de alerta para mudar essa postura aparece quando o APM consistentemente diz “o serviço X está lento” e ninguém consegue explicar por quê.
Quando continuous profiling é insubstituível
Alguns problemas simplesmente não aparecem nas métricas que o APM coleta. Por exemplo: um vazamento de memória que cresce 200MB por hora em um serviço Java, mas que ainda fica abaixo do heap limit. O APM não acende alerta nenhum até o GC começar a sufocar a aplicação. O profiling de heap detecta o crescimento desde o primeiro release.
Outro caso clássico é a degradação silenciosa de CPU após um deploy. Imagine um pull request que muda a serialização JSON e dobra o tempo de CPU. A latência média não muda porque o serviço estava com folga de hardware. O APM não vê o problema. Em contrapartida, o diff de perfis antes e depois mostra exatamente qual função passou a pesar.
Outros casos clássicos entram nessa categoria. Lock contention em sistemas multi-thread degrada throughput sem aparecer no APM. Cold start em funções serverless aparece como latência inexplicada na cauda da distribuição.
Adicionalmente, hotspots de alocação disparam GC pause sem ultrapassar limites de heap. Regressões de performance em código gerado por IA passam despercebidas até o custo de cloud subir sem explicação.
Por que os dois juntos formam o fluxo de troubleshooting mais rápido
Quando a operação combina APM e continuous profiling, o fluxo de investigação muda de formato. O alerta dispara via APM, que aponta o serviço e a janela de tempo. Em seguida, o engenheiro abre o profile daquele serviço naquela mesma janela e olha o flame graph. O caminho do alerta até a função culpada vira uma sequência de cliques.
Esse modelo aparece em iniciativas de padronização recentes. A especificação de profiles do OpenTelemetry define profiles como o quarto sinal de telemetria ao lado de métricas, logs e traces. A ideia central é correlacionar todos os sinais por trace ID e timestamp, permitindo ir do span direto para o perfil sem trocar de ferramenta.
Cada um desses sinais responde uma camada da pergunta “o que aconteceu”. Para entender como essas camadas se complementam, vale revisar o conceito mais amplo em o que é observabilidade. Em sistemas modernos, ignorar uma camada significa aceitar pontos cegos previsíveis.
Ferramentas representativas de cada categoria
No lado de APM, os players consolidados são Datadog APM, New Relic, Dynatrace e Elastic APM. Todos oferecem distributed tracing, mapa de serviços, alertas de SLA e integração com métricas e logs. As diferenças aparecem em preço, profundidade de integração com cloud providers e qualidade da UX de exploração de traces.
No lado de continuous profiling, o ecossistema é mais jovem porém já tem opções maduras. Grafana Pyroscope (OSS) lidera em adoção, com suporte amplo a linguagens via SDK. Parca (CNCF) entrega profiling via eBPF sem instrumentar código. Elastic Universal Profiling oferece coleta agentless em larga escala. Polar Signals Cloud é uma opção comercial baseada em Parca.
Em paralelo, fornecedores tradicionais de APM têm adicionado profiling como módulo opcional. Datadog Continuous Profiler e New Relic Continuous Profiler ilustram essa convergência. A vantagem da abordagem consolidada é a correlação automática entre trace e profile. A desvantagem é o vendor lock-in e o custo somado.
Para um panorama mais amplo de ferramentas da camada de aplicação, o guia de monitoramento de aplicações compara cenários e critérios de escolha por categoria.
Como decidir o que adotar primeiro
Para quem ainda não tem nem um nem outro, o caminho honesto é começar por APM. A razão é simples: APM resolve mais classes de incidente, tem maturidade maior e custa menos esforço operacional para entrar em produção. O ROI inicial é alto e mensurável em redução de MTTR.
Para quem já tem APM e enfrenta incidentes onde “o serviço está lento e ninguém sabe explicar”, continuous profiling é o próximo investimento. Comece pelos serviços críticos onde o consumo de CPU é uma preocupação real e expanda só depois de validar o modelo operacional. Pyroscope ou Parca em ambiente Kubernetes é o ponto de entrada mais barato.
Vale destacar que adotar profiling sem capacidade de operar um quarto sinal de telemetria é receita para abandono. O time precisa saber ler flame graph, comparar perfis entre releases e correlacionar o profile com o trace. Sem essa fluência, a ferramenta vira ruído. Nesse cenário, a melhor escolha é amadurecer APM primeiro e adiar o profiling para o próximo ciclo.
Em projetos onde o trade-off entre as duas camadas exige olhar externo, a consultoria especializada em observabilidade em ambientes corporativos ajuda a desenhar o stack. O foco é estruturar o fluxo operacional antes de comprometer orçamento com licenças.
Logs, métricas e traces unificados para diagnóstico em profundidade.
Instrumentamos aplicações corporativas com OpenTelemetry para correlacionar eventos e acelerar a análise de causa raiz em produção.
Conclusão
APM e continuous profiling resolvem perguntas diferentes da mesma operação. O APM mostra onde a requisição perde tempo na arquitetura. Por outro lado, o profiling mostra qual código está consumindo CPU agora. Ambos têm overhead controlado para produção e ambos correlacionam com métricas e logs. A diferença está em granularidade e foco.
Em síntese, comece por APM se ainda não tem nenhum dos dois. Adicione continuous profiling quando o APM atingir o teto de profundidade que entrega. Mantenha os dois quando o objetivo for cortar MTTR ao mínimo possível. A decisão é cumulativa, não excludente.
Se sua operação precisa avaliar qual stack faz sentido para o ambiente, vale chamar quem já fez isso muitas vezes. O mesmo vale quando o APM já está em produção e o próximo passo é adicionar profiling de forma estruturada. Fale com um especialista da OpServices para mapear o cenário e encurtar o caminho até a visibilidade que falta.
Perguntas Frequentes
Qual a diferença entre continuous profiling e APM?
span e qual dependência consumiu tempo dentro de cada trace. Continuous profiling mede o que o código está fazendo. Coleta amostras de stack trace 24×7 e revela qual função consome CPU ou aloca memória em uma janela específica. APM ganha em contexto de negócio (usuário, rota, tenant). Continuous profiling ganha em profundidade até a linha de código. As duas tecnologias se complementam: o APM aponta onde investigar e o profiling explica o porquê.Continuous profiling é o quarto pilar da observabilidade?
Qual o overhead do continuous profiling em produção?
19 Hz por thread mantém overhead mínimo. Para a maioria dos casos, 19 a 49 Hz é o ponto ideal entre profundidade e custo.
