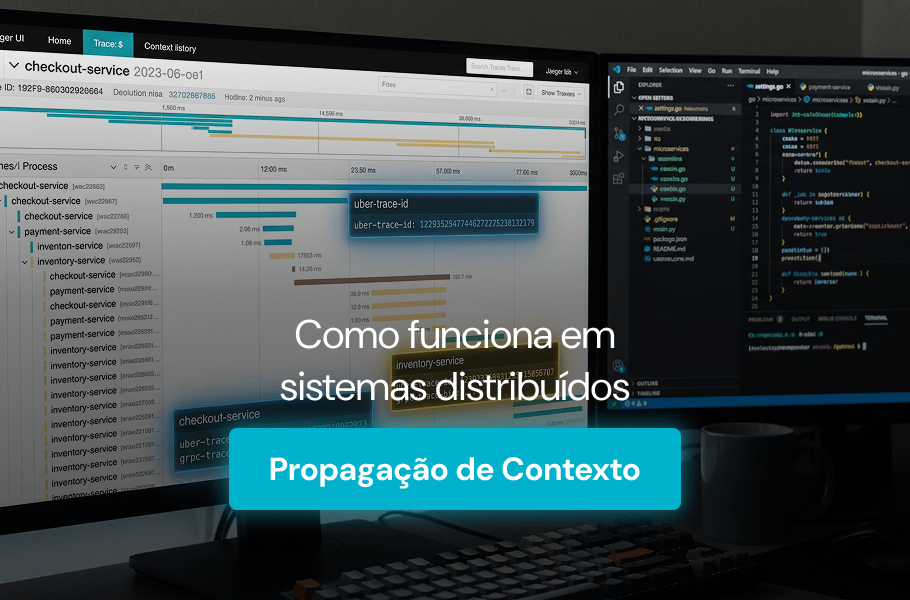
Quando uma requisição atravessa dezenas de microsserviços antes de retornar uma resposta ao usuário, identificar onde ocorre um gargalo de latência se torna um desafio real. É nesse cenário que entra o Jaeger, uma plataforma open source de rastreamento distribuído criada para dar visibilidade ao caminho completo de cada transação. Neste artigo, você vai entender […]