
Propagação de Contexto: como funciona em sistemas distribuídos
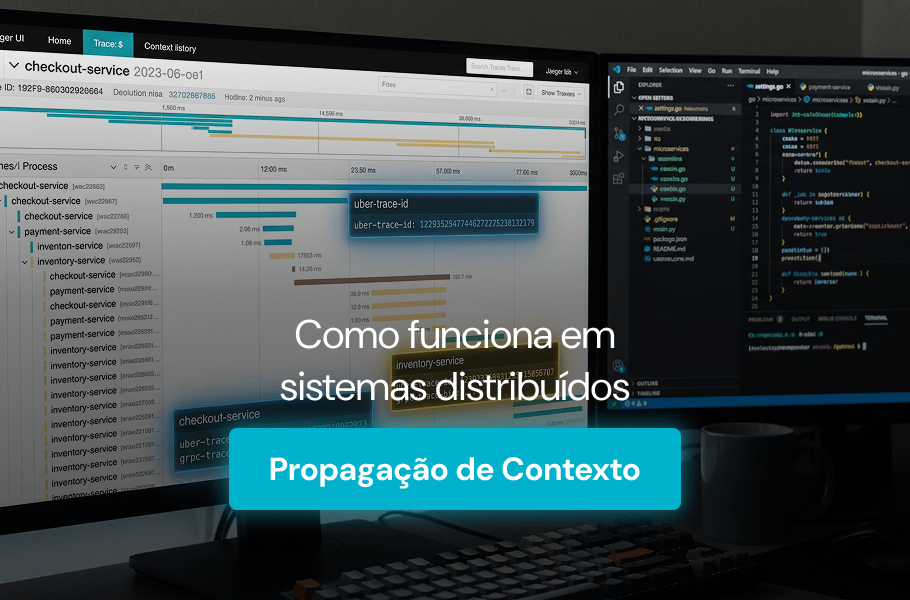
Quando uma requisição atravessa dezenas de microserviços, entender o caminho completo dessa jornada é o que separa equipes que resolvem incidentes em minutos daquelas que passam horas correlacionando logs manualmente. O mecanismo que torna isso possível tem um nome: Propagação de Contexto.
Sem esse mecanismo, cada serviço gera telemetria isolada. Métricas, logs e traces existem em silos separados, sem nenhuma ligação entre si. Com a propagação de contexto, todos esses sinais passam a compartilhar identificadores comuns que permitem reconstruir a história completa de cada transação.
Neste artigo, você vai entender o que é propagação de contexto, como ela funciona na prática, quais padrões existem e como implementá-la corretamente nos seus sistemas distribuídos.
O que é Propagação de Contexto
A propagação de contexto é o mecanismo que transporta metadados de rastreamento entre os componentes de um sistema distribuído. Esses metadados incluem identificadores como trace_id e span_id que permitem correlacionar eventos gerados por serviços diferentes dentro de uma mesma transação.
Pense em uma requisição que começa no frontend, passa por um API gateway, chega a um serviço de autenticação, consulta um banco de dados e dispara uma notificação assíncrona. Cada um desses componentes gera seus próprios dados de telemetria. A propagação de contexto é a “cola” que une todos esses fragmentos em uma narrativa coerente.
Esse conceito é um dos fundamentos da observabilidade em sistemas distribuídos. Sem ele, os três pilares da observabilidade — métricas, logs e traces — funcionam de forma desconectada.
Contexto vs propagação
É importante distinguir dois conceitos complementares. O contexto é a estrutura de dados que armazena informações sobre a operação corrente — como o identificador do trace, o span ativo e metadados adicionais (baggage). Já a propagação é o mecanismo que serializa esse contexto e o transmite entre processos, tipicamente via headers HTTP ou metadados de mensageria.
Dentro de um mesmo processo, o contexto trafega pela memória da aplicação. Entre processos diferentes, a propagação injeta o contexto no transporte de rede e o extrai do outro lado. Essa distinção é relevante porque cada cenário exige estratégias diferentes de implementação.
Como funciona a propagação de contexto na prática
O fluxo de propagação segue um padrão consistente independentemente da tecnologia utilizada. Ele pode ser resumido em quatro etapas: criação, injeção, extração e continuidade.
Na criação, o primeiro serviço que recebe a requisição gera um novo trace e atribui um trace_id único. Cada operação dentro desse serviço cria um span com seu próprio span_id.
Na injeção, quando o serviço faz uma chamada a outro serviço, o SDK de instrumentação serializa o contexto ativo e o adiciona aos headers da requisição HTTP, aos metadados gRPC ou aos atributos da mensagem em uma fila.
Na extração, o serviço receptor lê os headers, desserializa o contexto e reconstrói o estado do trace. O novo span criado nesse serviço é automaticamente vinculado como filho do span anterior.
Na continuidade, o processo se repete em cada salto da requisição. Ao final, o backend de observabilidade agrupa todos os spans pelo trace_id compartilhado e reconstrói a linha do tempo completa.
Padrões de propagação: W3C Trace Context e B3
Existem diferentes formatos para codificar o contexto nos headers de transporte. Os dois mais relevantes são o W3C Trace Context e o B3.
W3C Trace Context
O padrão definido pelo W3C é o formato recomendado pelo ecossistema OpenTelemetry. Ele utiliza dois headers HTTP:
traceparent carrega o identificador do trace, o identificador do span pai e as flags de amostragem em um formato compacto: 00-{trace_id}-{parent_id}-{trace_flags}.
tracestate permite que fornecedores adicionem informações proprietárias sem quebrar a interoperabilidade. Cada fornecedor insere um par chave-valor separado por vírgula.
A grande vantagem do W3C Trace Context é a interoperabilidade. Serviços instrumentados com bibliotecas diferentes conseguem participar do mesmo trace sem configuração adicional, desde que todos respeitem o padrão.
B3 Propagation
O formato B3 foi popularizado pelo Zipkin e ainda é amplamente utilizado. Ele usa headers separados como X-B3-TraceId, X-B3-SpanId e X-B3-Sampled, ou um header único b3 que condensa tudo em uma string.
B3 funciona bem em ambientes que já utilizam Zipkin ou sistemas legados. No entanto, para novas implementações, o W3C Trace Context é a escolha recomendada.
Baggage
Além dos identificadores de trace, existe o conceito de baggage — pares chave-valor arbitrários que viajam junto com o contexto. Baggage permite propagar informações de negócio, como ID do cliente, região ou prioridade da requisição, sem precisar alterar a interface dos serviços intermediários.
O OpenTelemetry suporta baggage nativamente, mas é preciso cautela: cada par chave-valor adicionado é transmitido em todos os saltos da requisição, o que pode aumentar o tamanho dos headers e gerar overhead em cenários de alto volume.
Propagação automática vs manual
Na maioria dos frameworks modernos, a propagação acontece de forma automática. SDKs como o OpenTelemetry instrumentam bibliotecas HTTP, gRPC e de mensageria para injetar e extrair contexto sem que o desenvolvedor escreva código adicional.
A propagação automática cobre cenários comuns: chamadas HTTP entre serviços, requisições gRPC e clients de banco de dados instrumentados. Ela reduz o esforço de adoção e diminui o risco de erros manuais.
Já a propagação manual é necessária quando o contexto precisa atravessar limites que a auto-instrumentação não cobre. Exemplos incluem: processamento em thread pools customizadas, callbacks assíncronos, protocolos proprietários e integrações com sistemas legados que não suportam headers padrão.
Na prática, a maioria das implementações combina os dois modos. A auto-instrumentação cobre 80-90% dos cenários, enquanto a instrumentação manual fecha as lacunas restantes em pontos específicos do código.
Propagação além do HTTP: gRPC, filas e jobs assíncronos
HTTP não é o único protocolo em um sistema distribuído. A propagação de contexto precisa funcionar em todos os canais de comunicação que a requisição atravessa.
gRPC
Em chamadas gRPC, o contexto é propagado via metadata — o equivalente dos headers HTTP no protocolo gRPC. O OpenTelemetry SDK injeta automaticamente os campos traceparent e tracestate nos interceptors do client e os extrai nos interceptors do server.
Filas de mensagens
Filas como Kafka, RabbitMQ e SQS introduzem um desafio adicional: a requisição original e o consumo da mensagem acontecem em momentos diferentes e em processos separados. O contexto é propagado nos atributos da mensagem (message attributes ou headers).
O ponto crítico é que o consumer group pode processar mensagens em ordem diferente ou em lotes. A instrumentação precisa vincular corretamente cada mensagem consumida ao span original do producer. Sem essa ligação, o trace é interrompido na fila e a cadeia de latência fica invisível.
Jobs assíncronos e scheduled tasks
Jobs em background representam outro cenário onde o contexto se perde com frequência. Quando uma requisição HTTP agenda um job para execução futura, o contexto precisa ser serializado e armazenado junto com os dados do job. Na execução posterior, o worker desserializa o contexto e o reativa antes de processar a tarefa.
Sem essa serialização explícita, o job cria um trace completamente novo sem vínculo com a requisição que o originou.
Desafios comuns e como resolver
Mesmo com a propagação configurada, existem cenários frequentes onde o contexto se perde ou se corrompe.
Thread pools e executors: muitas linguagens utilizam pools de threads para paralelismo. Quando uma tarefa é submetida a um executor, o contexto da thread original não é automaticamente copiado para a thread do pool. A solução é usar wrappers que capturam o contexto antes da submissão e o restauram na thread de execução. Em Java, o OpenTelemetry fornece o Context.wrap() para esse fim.
Serverless e FaaS: funções como AWS Lambda ou Azure Functions são efêmeras e podem não manter o contexto entre invocações. A estratégia é propagar o contexto via headers do evento de trigger (API Gateway, SQS, SNS) e restaurá-lo no início de cada execução da função.
Proxies e load balancers: intermediários de rede que não preservam headers customizados podem remover o traceparent. É essencial configurar proxies como Nginx, Envoy ou HAProxy para encaminhar os headers de trace sem modificação. O monitoramento de APIs ajuda a identificar rapidamente quando um intermediário está removendo esses headers.
Overhead de propagação: em sistemas com altíssimo throughput, o volume adicional de headers pode gerar impacto mensurável. Estratégias de sampling — como head-based sampling ou tail-based sampling — permitem reduzir o volume de traces coletados sem perder visibilidade sobre transações problemáticas. O monitoramento com alertas inteligentes complementa o sampling ao garantir que anomalias sejam detectadas mesmo quando nem toda transação gera um trace completo.
Boas práticas de Propagação de Contexto
Com base nos desafios observados em ambientes de produção, estas são as práticas recomendadas para uma implementação robusta:
Padronize o formato de propagação. Adote W3C Trace Context como formato principal em toda a organização. Se houver sistemas legados que usam B3, configure propagadores compostos que suportem ambos os formatos simultaneamente.
Inicialize o SDK de telemetria antes de qualquer import. Em linguagens como Node.js e Python, a auto-instrumentação funciona por monkey-patching das bibliotecas padrão. Se o SDK for inicializado após a importação dos módulos HTTP, a instrumentação não será aplicada corretamente.
Teste a propagação entre todos os canais. Não basta testar chamadas HTTP. Verifique que o contexto sobrevive a filas, jobs assíncronos, WebSockets e qualquer outro canal de comunicação presente na arquitetura.
Monitore traces quebrados. Configure alertas no seu backend de observabilidade para detectar spans órfãos — spans que referenciam um parent_id inexistente. Spans órfãos frequentes indicam que a propagação está falhando em algum ponto da cadeia.
Use baggage com moderação. Limite o baggage a informações essenciais que precisam estar disponíveis em todos os serviços da cadeia. Cada item adicionado ao baggage aumenta o tamanho de todos os headers em todos os saltos.
Documente os pontos de propagação manual. Onde a auto-instrumentação não funciona e a propagação manual foi implementada, documente o motivo e a solução adotada. Esses pontos são os mais propensos a regressões durante refatorações.
A adoção consistente dessas práticas garante que a documentação oficial do projeto de telemetria aberta seja complementada pela experiência operacional da sua equipe.
Logs, métricas e traces unificados para diagnóstico em profundidade.
Instrumentamos aplicações corporativas com OpenTelemetry para correlacionar eventos e acelerar a análise de causa raiz em produção.
Conclusão
A propagação de contexto é o alicerce que sustenta toda a cadeia de observabilidade em arquiteturas distribuídas. Sem ela, métricas, logs e traces existem como fragmentos desconectados que dificultam o diagnóstico e prolongam o tempo de resolução de incidentes. Com ela, cada requisição conta sua história completa desde a origem até a resposta final.
Implementar a propagação corretamente exige atenção a detalhes que vão além da configuração inicial: filas assíncronas, thread pools, proxies intermediários e funções serverless são pontos onde o contexto frequentemente se perde. A combinação de auto-instrumentação com intervenções manuais nos pontos críticos é a abordagem mais eficaz na prática.
Se a sua organização está construindo ou aprimorando a estratégia de observabilidade e precisa de apoio para instrumentar aplicações e garantir a propagação de contexto entre todos os componentes, fale com os especialistas da OpServices. Nossa equipe ajuda empresas a transformar telemetria fragmentada em visibilidade operacional completa.
Perguntas Frequentes
Qual a diferença entre tracing distribuído e propagação de contexto?
trace_id, span_id) entre os serviços via headers. Sem propagação de contexto, o tracing distribuído não funciona — cada serviço geraria traces independentes sem correlação entre si.Como o OpenTelemetry implementa a propagação de contexto?
Como funciona o W3C Trace Context?
traceparent transporta o trace_id (identificador do trace), o parent_id (span que originou a chamada) e as trace_flags (decisão de sampling). O tracestate permite que fornecedores diferentes adicionem metadados proprietários. Esse padrão garante interoperabilidade: serviços instrumentados com bibliotecas diferentes participam do mesmo trace automaticamente.
