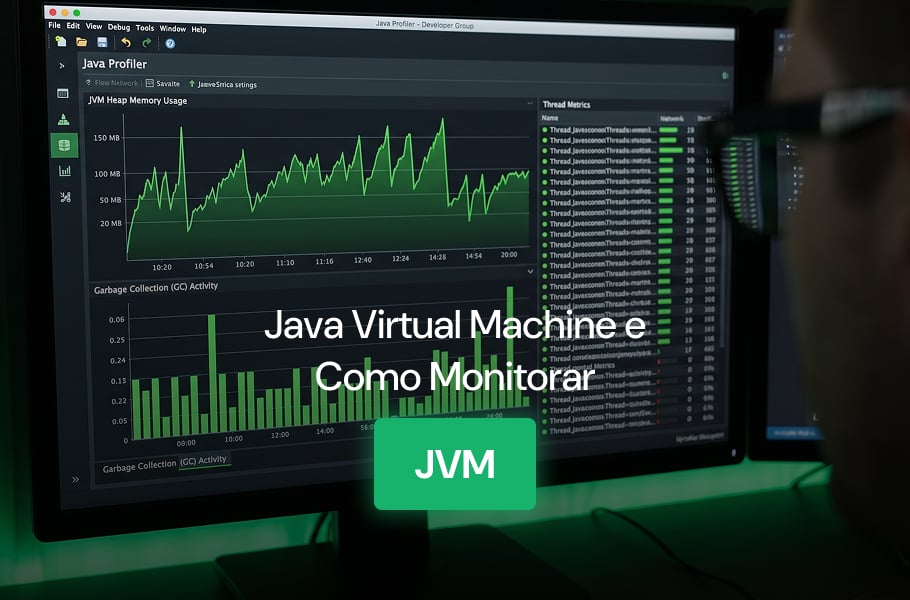
Cargas de IA e Machine Learning mudaram a equação de capacidade nos data centers brasileiros. Treinar um modelo de detecção de fraude exige horas seguidas de GPU em utilização plena, e cada minuto ocioso vira desperdício direto no orçamento de infraestrutura. Mesmo assim, a maioria das equipes ainda observa GPU com os mesmos dashboards de […]