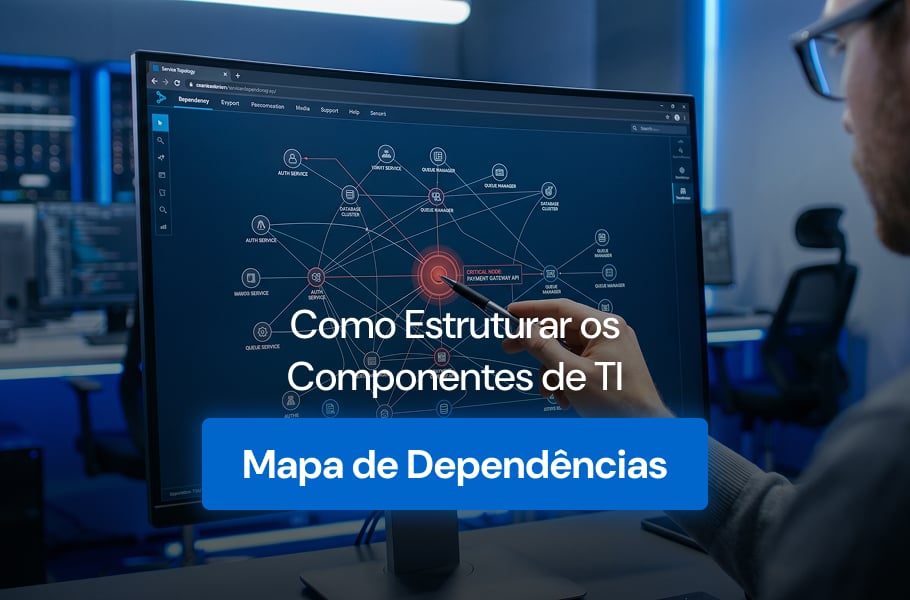
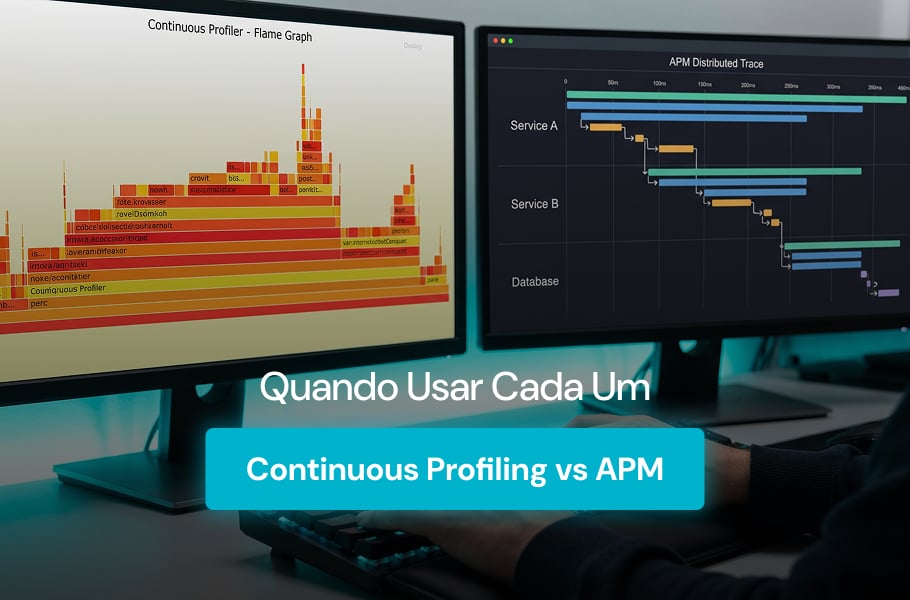
Para times de TI, a sigla CVE aparece em todo alerta de segurança, em cada boletim de patch e em qualquer radar de risco. Por trás dela, existe um sistema global que padroniza como o mundo identifica falhas em software e hardware. Sem essa padronização, cada fornecedor descreveria a mesma vulnerabilidade de um jeito diferente. […]