
Mapa de Dependências: Como Estruturar os Componentes de TI?
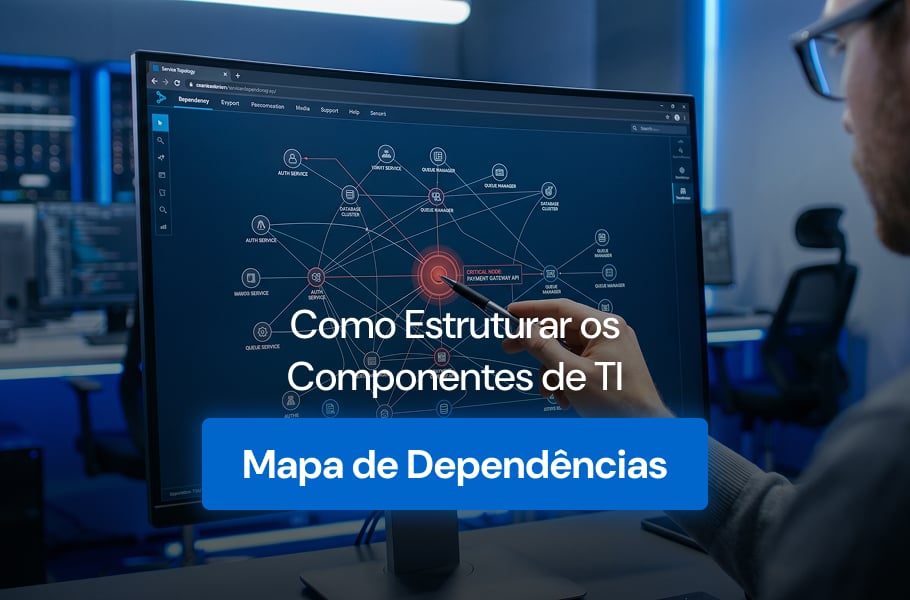
Operações de TI modernas convivem com centenas de aplicações, serviços e integrações que dependem umas das outras a todo instante. Quando algo quebra, o time precisa descobrir rapidamente onde a falha começou. Sobretudo, precisa saber quem mais está afetado.
O mapa de dependências responde exatamente a essas duas perguntas. Em vez de mergulhar em logs isolados ou abrir dezenas de dashboards, o operador visualiza as relações entre serviços, infraestrutura e aplicações em uma única tela.
Neste guia, você entende o que é um mapa de dependências e como ele se diferencia do CMDB. Em seguida, vê quais tipos existem, como funciona a descoberta automática e quais passos seguir para implementar em ambientes híbridos e multicloud.
O que é um mapa de dependências?
Um mapa de dependências é a representação visual das relações entre componentes de um ambiente de TI. Cada nó representa um serviço, aplicação ou item de infraestrutura. As arestas indicam como esses nós se comunicam, consomem ou dependem uns dos outros.
Por trás dessa imagem aparentemente simples existe uma fonte de verdade operacional. Em ambientes monolíticos antigos, o mapa cabia em uma planilha. Hoje, com microsserviços, multicloud e SaaS, a complexidade explodiu e o mapa virou um requisito de sobrevivência.
Em síntese, o mapa responde três perguntas críticas. Quem depende deste serviço, do que ele depende e qual o caminho da requisição até o usuário final.
Por isso, equipes de operações e de monitoramento de TI usam o mapa para acelerar diagnóstico. Além disso, ele ajuda a priorizar incidentes pelo impacto real e a ganhar contexto antes de qualquer mudança em produção.
Diferenças do Mapa de dependências, CMDB e topologia de rede
Confundir mapa de dependências com CMDB ou topologia de rede é comum, mas atrapalha tanto o investimento quanto o uso. Cada conceito ocupa um lugar diferente na operação.
O CMDB armazena itens de configuração e seus relacionamentos como dados estruturados, com foco em governança e ITIL. Por outro lado, a topologia de rede mostra como roteadores, switches e enlaces se conectam física ou logicamente.
Já o mapa de dependências reúne todas as relações entre serviços, aplicações, bancos, APIs externas e infraestrutura. Em seguida, atualiza esses vínculos em tempo quase real. Em outras palavras, é a visão operacional dinâmica, enquanto o CMDB é o repositório estático.
A tabela abaixo resume as três diferenças que mais importam no dia a dia da operação.
| Dimensão | Mapa de dependências | CMDB | Topologia de rede |
|---|---|---|---|
| Foco principal | Relações dinâmicas entre serviços e infraestrutura | Itens de configuração e governança ITIL | Conexão física e lógica de equipamentos |
| Atualização | Tempo quase real, via descoberta automática | Periódica, com forte componente manual | Variável: dinâmica via SNMP, manual no físico |
| Pergunta que responde | “O que afeta o quê neste momento?” | “Quais ativos temos e como se relacionam?” | “Como o tráfego flui entre dispositivos?” |
| Forma de visualização | Grafo interativo dirigido | Banco relacional e dashboards de relatório | Diagrama de rede e mapa de calor |
Tipos de mapa de dependências
Nem todo mapa de dependências mostra a mesma coisa. Conforme o foco da operação, cinco tipos costumam aparecer no portfólio de uma equipe madura.
A diferença entre eles vai além do diagrama. Cada tipo responde a uma pergunta operacional diferente e times maduros costumam manter mais de um em paralelo.
| Tipo | Foco | Quando usar |
|---|---|---|
| Mapa lógico | Relações entre serviços e funções, independente da infraestrutura física | Arquitetura e desenvolvimento |
| Mapa físico | Equipamentos, racks, servidores e cabeamento | Data center e infraestrutura física |
| Mapa de aplicações | Componentes internos: microsserviços, filas e bancos | SREs e times de aplicação |
| Mapa de serviços | Vínculo entre serviços de negócio e componentes técnicos | CIO, ITSM e alinhamento com áreas de negócio |
| Mapa transacional | Caminho real percorrido por uma requisição, derivado de traces | Diagnóstico fino e análise de causa raiz |
Em projetos novos, escolher dois ou três tipos compatíveis com a realidade da equipe entrega valor mais rápido. Tentar implementar todos de uma vez costuma travar o cronograma.
Como funciona a descoberta automática
Manter um mapa de dependências manual em ambiente moderno é praticamente inviável. As relações mudam toda semana, deploys novos criam endpoints inéditos e integrações SaaS aparecem sem aviso.
Por isso, a descoberta automática virou a norma. Quatro abordagens se destacam, cada uma com prós, contras e cenário ideal.
| Método | Como descobre | Quando usar |
|---|---|---|
| Agentes em hosts | Inspecionam processos, conexões TCP e bibliotecas carregadas |
Servidores tradicionais e cargas legadas |
| Traces distribuídos | Cada requisição carrega um trace ID via OpenTelemetry e liga serviços em cascata | Microsserviços e aplicações instrumentadas |
| eBPF no kernel Linux | Captura syscalls e tráfego em nível de kernel, sem agente intrusivo (fundamentos do eBPF) | Kubernetes e cenários com alta densidade de containers |
| sFlow, NetFlow e fluxo de rede | Análise de pacotes amostrados em switches e roteadores | Comunicação entre subnets e dispositivos não instrumentáveis |
Cada técnica enxerga uma camada diferente da pilha. Combinar duas ou três delas costuma entregar a cobertura mais realista e revela dependências que ferramentas isoladas deixam escapar.
Em ambientes onde o monitoramento de tráfego de redes já existe, aproveitar a coleta de fluxo é o primeiro passo de baixo atrito. Quando há instrumentação madura, traces via documentação oficial da plataforma de observabilidade aberta entregam o mapa mais rico.
Benefícios operacionais: do MTTR à gestão de mudanças
Investir em um mapa de dependências sem clareza sobre o retorno é um caminho rápido para o projeto morrer no orçamento do ano seguinte. Por isso vale conectar cada benefício a uma métrica operacional concreta.
| Benefício | Métrica afetada | Impacto típico |
|---|---|---|
| Análise de causa raiz | MTTD e MTTR |
Reduz o tempo de identificação ao revelar a origem da cadeia |
| Gestão de mudanças | Taxa de mudanças com falha | Aumenta o sucesso ao expor impactos colaterais antes do deploy |
| Resposta a incidentes | Horas em war room | A equipe entra no incidente já com escopo de impacto definido |
| Planejamento de capacidade | Custo cloud e desperdício | Revela consumo desbalanceado e dependências subaproveitadas |
| Onboarding de SRE | Tempo até produtividade | Novos engenheiros entendem a arquitetura sem tribal knowledge |
Esses ganhos não acontecem só na operação. Times de produto, segurança e arquitetura também consomem o mapa para tomar decisões com mais contexto. Equipes que combinam o mapa com APM conseguem correlacionar latência de transação com componentes problemáticos em segundos.
Em ambientes regulados como bancos, saúde e varejo, a tabela de impactos ainda alimenta evidências de auditoria e cumprimento de SLA contratual.
Como implementar em sete passos
Implementar mapa de dependências em larga escala é um projeto de longo prazo. No entanto, começar pequeno e iterar entrega valor desde o primeiro mês.
| # | Passo | Resultado esperado |
|---|---|---|
| 1 | Defina o objetivo principal | Reduzir MTTR, apoiar mudanças ou mapear riscos define o escopo |
| 2 | Mapeie o legado existente | Reuso de CMDB, planilhas e documentação acelera entregas |
| 3 | Escolha o método de descoberta | Agentes, traces, eBPF ou fluxo, conforme o ambiente predominante |
| 4 | Comece por um domínio crítico | Caminho completo front, back, banco e integrações de um serviço chave |
| 5 | Valide com quem opera | O mapa só vale quando o plantão concorda com as relações |
| 6 | Integre com APM, ITSM e CMDB | Ganchos com sistemas existentes evitam silos e duplicidade |
| 7 | Estabeleça rotina de revisão | Revisão mensal ou trimestral mantém o mapa confiável |
Vale destacar que a integração com observabilidade no passo 6 entrega o ciclo completo. O mapa contextualiza, traces explicam, métricas quantificam e logs detalham o que aconteceu em cada nó.
Armadilhas comuns em ambientes híbridos e multicloud
Cada ambiente híbrido carrega armadilhas próprias. Conhecer as mais comuns antes do projeto evita meses de retrabalho e perda de credibilidade do mapa dentro da operação.
| Armadilha | Sintoma típico | Como evitar |
|---|---|---|
| Dependências entre clouds invisíveis | Falhas em produção sem alerta no provedor de origem | Forçar a descoberta a percorrer tags e workspaces em todas as nuvens |
| APIs SaaS como ponto cego | Lentidão repentina em fluxos com dependências externas | Instrumentar chamadas SaaS no APM e listar contratos no mapa |
| Mudanças não propagadas | Diagrama bonito mas obsoleto, a equipe perde confiança | Integrar o pipeline CI/CD ao mapa, gerar evento a cada deploy |
| Confiança cega na descoberta | Relações importantes omitidas por amostragem incompleta | Combinar dois métodos e validar com revisão da equipe a cada trimestre |
| Mapa virando vitrine | Diretoria adora, operação ignora no plantão | Vincular o mapa aos rituais reais: postmortem, mudança e escalação |
Sobretudo, manter o mapa amarrado ao monitoramento em tempo real garante que o diagrama reflita cada alteração relevante em minutos. Ambientes onde isso falha acabam revertendo ao caos de planilhas em poucos meses.
Vale citar também a definição de ADDM da Gartner como referência conceitual para conversas com stakeholders menos técnicos.
Assumimos o NOC da sua empresa para acionamento e escalação 24/7.
Monitoramento contínuo de infraestrutura, triagem de incidentes por severidade e escalação inteligente com MTTD e MTTR mensuráveis.
Conclusão
Um mapa de dependências bem feito muda o jogo da operação. Em vez de reagir a alertas isolados, a equipe enxerga sistemas como uma rede de relações dinâmicas e age sobre causa, não sintoma.
Vale começar simples. Escolha um domínio crítico, instrumente o método de descoberta compatível com seu ambiente e amarre o mapa às rotinas reais do plantão. Em poucas semanas, os ganhos em MTTR e em conversas estratégicas com o negócio começam a aparecer.
À medida que o ambiente cresce em cloud, microsserviços e SaaS, o mapa deixa de ser apenas ferramenta operacional. Posteriormente, ele se torna ativo de governança, segurança e arquitetura.
Se sua equipe precisa estruturar essa visão em larga escala e ainda não sabe por onde começar, fale com um especialista da OpServices. Em poucas conversas, dá para mapear o caminho mais curto sem subestimar a complexidade do ambiente.

