
A ideia, devo confessar, não é minha, mas do amigo e brilhante SRE (Site Reliability Engineering) da Globo.com, Alessandro Ren. Ele discutiu comigo a relação do trabalho de SRE e a catástrofe que atingiu o RS nestes últimos dias e parece ainda longe de acabar.
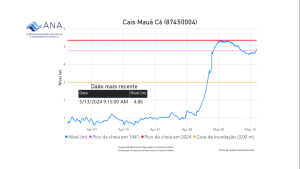
Pois bem, a história da catástrofe em Porto Alegre começou em 1941 com a grande enchente que ocorreu naquele ano e destruiu diversas áreas importantes da cidade, isso numa época em que nem se pensava ou falava em aquecimento global. Pois bem, nos anos seguintes foi feito um postmortem, não sei se com ou sem uma postura de encontrar culpados (blameless), do problema e aqui começam as semelhanças com o trabalho dos SREs. Se na época foi feita uma análise das causas do problema e as possíveis soluções para mitigar futuros desastres. Fato é que um relatório de postmortem foi gerado apontando um plano com ações práticas.
Seguindo o rumo do plano, o estado do RS contratou uma empresa de engenharia da Alemanha para um fazer um projeto de uma obra que impedisse novamente uma enchente como a de 1941. E assim foi feito, a empresa fez o projeto que resultou em todo um sistema de diques e no mal falado muro da Mauá que por muito tempo isolou o centro da cidade ao acesso visual ao Guaíba. Pelo que consta, muitas coisas foram deixadas de lado no projeto do sistema de contenção, por questões de custo e (como sempre) por razões políticas. Isso aconteceu na década de 60/70 e felizmente, até agora, Porto Alegre nunca mais havia sofrido uma enchente tão devastadora, o que fez inclusive que muita gente questionasse a utilidade do sistema de proteção.
O que aconteceu de lá pra cá é que as manutenções foram sendo deixadas de lado por sucessivos governos (e por falta de cobrança da sociedade civil) e quando finalmente foi necessário, o sistema de proteção de enchentes não foi efetivo, com muitos pontos de falhas, seja na vedação dos portões (que no projeto original nem deveriam existir) mas principalmente nas casas de bombas que deveriam levar a água da cidade para o rio (ou lago) e assim manter a cidade a salvo da inundação. O resultado, estamos dolorosamente assistindo e sofrendo.
Já dá pra perceber as semelhanças quando ocorre um problema com as aplicações que apresentam defeitos em produção ? Foi feito um postmortem em sua empresa para analisar as causas e preparar um plano de ação ? O plano de ação foi implementado ?
Voltando à relação com os serviços de SRE, faltou uma observabilidade e métricas mais precisas dos indicadores de desastre, o que poderia ter sido feito tanto pela medida do índice pluviométrico quanto do nível estimado de subida dos rios e do lago Guaíba. Numa analogia simplista, uma plataforma de observabilidade das métricas (SLIs) de:
- Índice pluviométrico nos rios que alimentam o lago,
- Razão de subida dos rios e do lago,
- Direção e intensidade dos ventos.
Estas métricas poderiam indicar o que estava por acontecer. Este poderia ser o SLO da observabilidade proposta, ou seja, não permitir que a cidade tenha uma elevação maior do que 10 cm de água do que está abrigado dentro do sistema de contenção. Não se trata de futurologia mas de análise dos indicadores que já existiam (ou deveriam existir) e que poderiam ter salvo muitas vidas e recursos. O uso de um modelo de IA com os dados telemétricos poderia ainda ter ajudado a antecipar as ações de mitigação, coisa que não existia em 1941. O mesmo pode-se dizer de uma aplicação em sua empresa. Com a correta definição de indicadores e objetivos de negócios é possível observar o comportamento da aplicação para detectar anomalias e fazer correções antes que a mesma fique indisponível e traga prejuízos ao negócio.
O SLO poderia ser de 100%, ou no caso 0 cm de água ? Poderia, mas o custo seria inviável, pois a solução para ter 0% de água poderia ser elevar toda a cidade a 10m do solo, estaríamos a salvo da enchente, mas a que custo ? Então, estes 10 cm de água seriam o nosso orçamento de erro (error budget). Lembrando que as boas práticas de SRE recomendam que não se deve perseguir 100% de disponibilidade, pois no mundo real, 100% de disponibilidade inibem a inovação e em nossa analogia simplista, poderiam impedir a cidade de crescer ou construir algo diferente.
A construção dos SLIs e SLOs vai passar necessariamente pela análise do mapa de riscos da cidade, e por conseguinte, quanto a população e seus governantes estão dispostos a pagar para ter uma cidade a prova de desastres? Lembrando que os custos das infraestruturas fatalmente serão pagos por nossos impostos.
Outro ponto importante para falarmos em um próximo post seria a aplicação do chaos engineering para testes de stress dos planos de contingenciamento. Claro que inundar a cidade para testar os pontos de stress não seria uma possibilidade, mas aplicar modelos de AI/Machine Learning, onde hipóteses de caos possam ser realizados, como, simular a falha de casa de bombas, níveis pluviométricos e até mesmo falhas em diques, podem nos gerar insights sobre pontos de melhoria no sistema de prevenção além de alertas de evacuação mais eficientes.
Enfim, esta é uma analogia simplista de como a observabilidade pode nos ajudar a criar estruturas e aplicações resilientes. Práticas de SRE podem nos ajudar a entender como podemos ser mais resilientes em relação aos sistemas e assim mitigar riscos nos negócios. Espero que nos próximos meses seja feito um postmortem adequado do desastre, sem procurar culpados (não vai adiantar nada) mas focado do entendimento das falhas, e que daí surja um plano de ação para mitigar os riscos de uma nova catástrofe, mas principalmente que este plano seja implementado, mantido e observado. Não creio que a catástrofe poderia ser evitada, a conjunção de fatores climáticos criou a tempestade perfeita, mas não tenho dúvidas que poderia ser minimizada.
Falando nisso, já fez sua doação às vítimas da enchente ? Estamos precisando…
SRE and the flood tragedy in Southern Brazil: An Analogy for Resilience
The idea, I must say, is not mine, but that of my friend and brilliant SRE (Site Reliability Engineering) from Globo.com, Alessandro Ren. He discussed with me the relationship between SRE work and the catastrophe that has hit our state in southern Brazil in recent days and which still seems far from over.
Well, the story of the catastrophe in Porto Alegre began in 1941 with the great flood that occurred that year and destroyed several important areas of the city, at a time when global warming was not even thought of or talked about. In the following years a postmortem was carried out, I don’t know if with or without a blameless stance, on the problem and here the similarities with the work of SREs begin. At the time, an analysis was made of the causes of the problem and possible solutions to mitigate future disasters. The fact is that a postmortem report was generated pointing out a plan with practical actions.
Following the plan, the state of RS hired an engineering company from Germany to design a project that would once again prevent a flood like the one in 1941. And so it was done, the company created the project that resulted in a whole dike system and the much-noticed Mauá wall that for a long time isolated the city center from visual access to Guaíba. Apparently, many things were left aside in the design of the containment system, for cost reasons and (as always) for political reasons. This happened in the 60/70s and fortunately, until now, Porto Alegre had never suffered such a devastating flood again, which even made many people question the usefulness of the protection system.
What has happened since then is that maintenance was left aside by successive governments (and due to a lack of demand from civil society) and when it was finally necessary, the flood protection system was not effective, with many points of failure, whether in the sealing of the gates (which in the original project should not even exist) but mainly in the pump houses that should take the city’s water to the river (or lake) and thus keep the city safe from flooding. As a result, now we are painfully watching and suffering.
Can you already see the similarities when there is a problem with applications that have defects in production? Was a postmortem process carried out in your company to analyze the causes and prepare an action plan? Has the action plan been implemented? Has the plan tested ?
Returning to the relationship with SRE services, there was a lack of observability and more precise metrics for disaster indicators, which could have been done both by measuring the rainfall index and the estimated level of rise of the rivers and Lake Guaíba. In a simplistic analogy, a metrics observability platform (SLIs) of:
- Rainfall level and predicted in the rivers that feed the lake,
- Rate of rise of rivers and lakes,
- Wind direction and intensity.
These metrics could indicate what was about to happen. This could be the SLO of the proposed observability, that is, not allowing the city to have an elevation greater than 10 cm of water than is sheltered within the containment system. This is not about futurology but about analyzing the indicators that already existed (or should have existed) and that could have saved many lives and resources. The use of an AI model with telemetry data could also have helped to anticipate mitigation actions, something that did not exist in 1941. The same can be said about an application in your company. With the correct definition of business indicators and objectives, it is possible to observe the behavior of the application to detect anomalies and make corrections before it becomes unavailable and causes losses to the business.
Could the SLO be 100%, or in this case 0 cm of water? It could, but the cost would be unfeasible, as the solution to having 0% water could be to raise the entire city 10m above the ground, we would be safe from flooding, but at what cost? So, these 10 cm of water would be our error budget. Remembering that good SRE practices recommend that you should not pursue 100% availability, as in the real world, 100% availability inhibits innovation and in our simplistic analogy, could prevent the city from growing or building something different.
The construction of SLIs and SLOs will necessarily involve analyzing the city’s risk map, and therefore, how much are the population and their governments willing to pay to have a disaster-proof city? Remembering that infrastructure costs will inevitably be paid by our taxes.
Another important point to talk about in a future post would be the application of chaos engineering for stress testing of contingency plans. Of course, flooding the city to test stress points would not be a possibility, but applying AI/Machine Learning models, where hypotheses of chaos can be realized, such as simulating the failure of a pump house, rainfall levels and even failures in dikes, can give us insights into points for improvement in the prevention system in addition to more efficient evacuation alerts.
Anyway, this is a simplistic analogy of how observability can help us create resilient structures and applications. SRE practices can help us understand how we can be more resilient in relation to systems and thus mitigate business risks. I hope that in the coming months a proper postmortem of the disaster will be carried out, without looking for blame (it won’t do any good) but focused on understanding the flaws, and that an action plan will emerge to mitigate the risks of a new catastrophe, but mainly that this plan is implemented, maintained and observed. I don’t believe the catastrophe could be avoided, the combination of climatic factors created the perfect storm, but I have no doubt it could be minimized.
And talking about disaster, have you already made your donation to the flood victims? We are in need…









